Scaling I/O for Commodity Clusters
Proposal No. 08-0861
1. Overview of
the Problem and Idea
The goal of this LDRD is to create a high performance parallel file system that is an integral part of the mainline Linux kernel. While specialized distributed parallel filesystems have been developed outside of the Linux main stream, they have not proven to be satisfactory from the standpoint of support, reliability, and performance. The Linux community is improving the kernel-standard NFS file system, but the work is not aimed at HPC needs. In order to address the HPC community, a new type of NFS, called Parallel NFS, or pNFS, has been proposed. One obstacle in scaling pNFS for HPC is the performance bottleneck in NFS streaming-writes, which stems from Linux’s NFS implementation and its interaction with the Linux virtual file system (VFS) and virtual memory management system (VMM). Write throughput is strongly affected by the lack of concurrency between application I/O and the implementation's effect of stalling writers while flushing cached data.
We identify two strategies to optimize streaming writes on the client side. First, re-implement the Linux NFS client to be procedure-based, multi-threaded and asynchronous. The NFS client can then perform network I/O simultaneously with the application data writing on multi-core machines. Second, improve the behavior of the Linux VFS and VMM to increase overlapping of application and network I/O.
This work is being done in collaboration with industry leaders in the computing field. Few organizations can test and develop on the scale of Sandia; hence our involvement in this work is essential to its success. If we succeed, there are many organizations in the HPC and other fields who will benefit from our work, since it will be integrated into the mainline Linux kernel, and hence available to all Linux users.
2. R&D Accomplishments: Progress toward Milestones
Our first year plan is to understand and explain the NFS client side bottlenecks and propose a resolution. Performance debugging data will be generated with instrumented source code of the NFS server, the NFS client, and the Linux file and cache subsystems while running performance benchmarks.
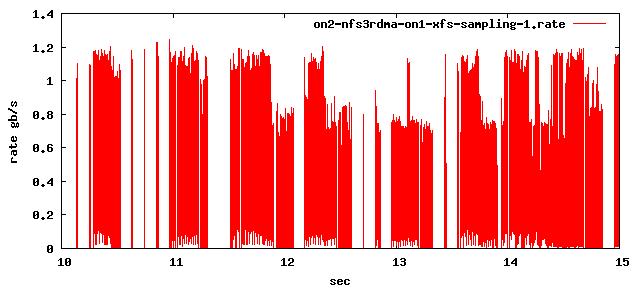
Figure 1 I/O Profile of NFS Streaming Write
We developed a light-weight, high-resolution profiling tool to capture the I/O behavior of a large NFS streaming write (Figure 1). We observe that NFS’s streaming-write is periodically throttled. We used collectl, a public domain monitoring tool, to gather system statistics during a streaming-write in an attempt to identify and understand the bottlenecks in Linux kernel. Figure 2 depicts the dynamics between the CUP, Memory-cache, NFS-write, and the IB Network subsystems during the test. These plots clearly reflect the stop-and-go I/O profile demonstrated in Figure 1; when the usage of memory cache reaches the 34% threshold, Linux VMM throttles the application and starts to flush cached data through NFS writes, resulting in visible increases in network traffic. With sufficient cache memory reclaimed, the network traffic is stopped, and the CPU and memory cache usage starts to rise, indicating the start of the next iteration of application I/O; we see no overlapping between the application and the network I/O.
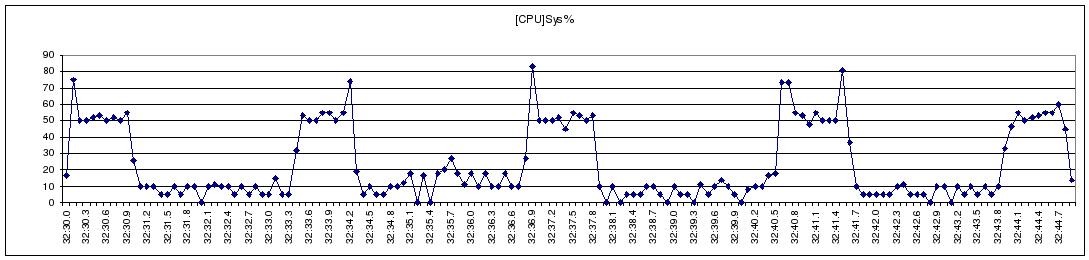
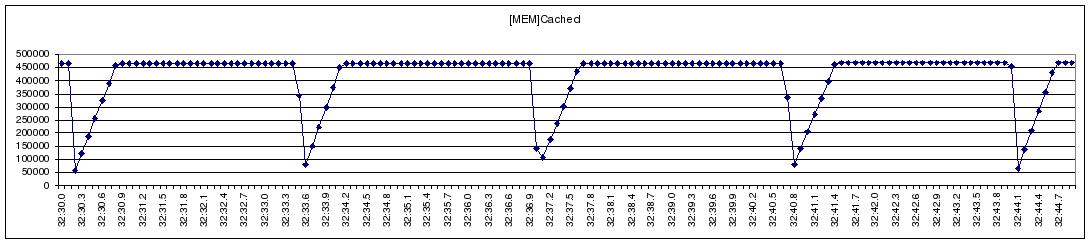
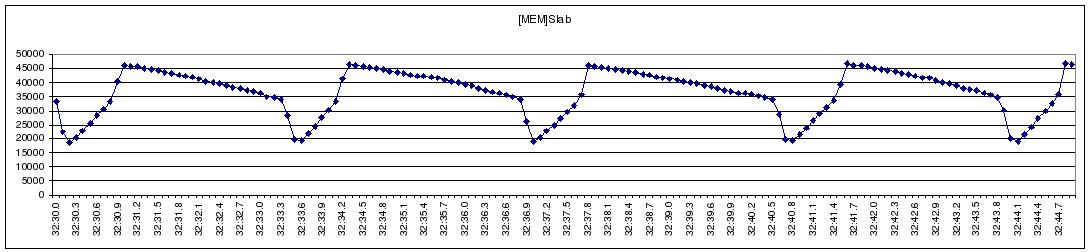
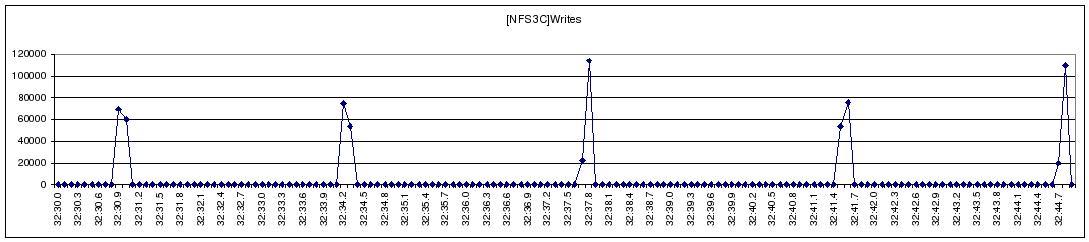
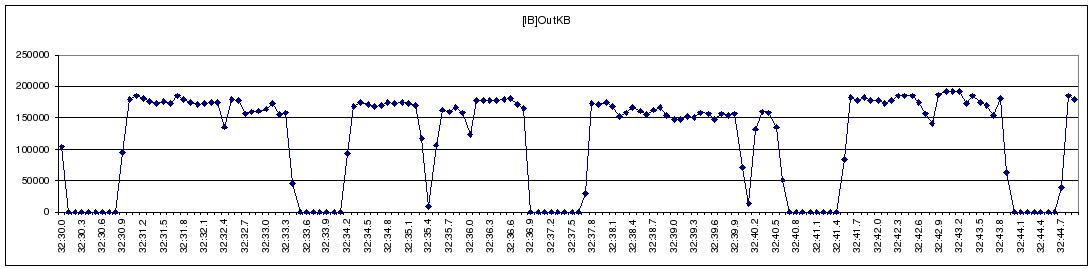
Figure 2 Collectl Statistics
We have also developed several kernel patches that allow us to “short circuit” parts of the NFS write path. For example, we can have the client code do every part of a write except the network RPC, or have the kernel code respond to a write RPC but not actually write the data on the server side. We have developed some preliminary results from this work, which, not surprisingly, show oscillations at every point in the path from client to server. The fine control which these modifications allow will also help to identify bottlenecks in the path. With bottlenecked kernel subsystems identified, we will then use the Linux Kernel Marker to trace kernel-user space interactions to debug the NFS write performance problem. We will record and analyze network and file system usage and efficiency, and then propose a solution to resolve the problem. Tutorial materials on our monitoring and kernel tracing tools, as well as more detailed results and plots are posted on http://gs.ca.sandia.gov/wiki/tiki-index.php?page=Scalable+IO.
Significant progress was also made since the start of this LDRD building community advocacy from UMICH, IBM, NetApp, and HP for changes to the Linux NFS that will enable open-source systems to achieve high streaming write throughput in HPC applications. We will publish our findings and proposed resolution in peer- reviewed conferences or journals
3. Proposed R&D
3.1 Key Project Goals and Milestones:
|
Goal |
Milestone |
Completion Date |
|
|
Identify bottlenecks |
|
Q2 2008 Q3 2008 Q4 2008 |
|
|
Implement and validate optimization strategies |
|
Q2 2009 Q1 2010 Q2 2010 |
|
|
Communicate results |
|
Q3 2010 Q4 2010 Q4 2010 |
3.2 Leading Edge Nature of Work:
The leading edge aspects of this work, to date, are in the development of new measurement tools, FTQ-IO, and techniques; the ability to combine several data sources to create very precise attribution of file system problems to kernel activities; kernel modifications to allow dynamic “short circuiting” of kernel activities to facilitate measurement.
The FTQ-IO measurements will allow us, for the first time, to create a rigorous time-domain measurements of performance that are amenable to signal processing approaches. We will also be running parallel FTQ-IO on clusters, as our interest is in whole-cluster file system performance, not just single CPU performance. IBM has indicated interest in using FTQ-IO for their cluster measurements. The FTQ-IO tool performs a fixed number of IO operations, until a fixed amount of time passes, as measured by the 2.5 GHz. time stamp counter. At the end of this loop, FTQ-IO reads kernel statistics via the Supermon kernel module. The use of the Supermon kernel module allows us to correlate user activity --writing a file-- with kernel measurements -- VM pages, free memory, and so on -- to within a very fine resolution. The measured time of the read system call for the kernel module is well under 50 ns. We can thus combine the user data with the kernel date very precisely, as the measurements are being made by one tool.
The kernel “short circuit” patches allow us, at the time a file system is mounted, to specify that certain operations will become no ops. We can very easily isolate kernel modules of interest and closely measure their impact on performance with FTQ-IO.
We will collaborate and consult with the Linux NFS, kernel, and network researchers at Network Appliance, Open Grid Computing, University of Michigan, Ohio State University, and the Open Fabrics Alliance, HP, and IBM in designing, testing, and building community support for changes to the Linux NFS that will enable open-source systems to achieve high streaming write throughput in HPC applications. We propose to study the new algorithms on HPC clusters not commonly available in the NFS and kernel developer communities, to demonstrate changes to the NFS implementation to remove the bottleneck in NFS writes, and to build community advocacy for having these HPC-favorable changes migrated into the Linux mainstream.
3.3 Technical Risk and Likelihood of Success:
There are two principal technical risks. The first risk is uncertainty in the depth of changes needed, if any, to the Linux VFS and VMM subsystems in order to support efficient streaming writes from an improved NFS client. The VMM affects all other subsystems and applications, so any change to it must be carefully tested. Our risk mitigation strategy is to implement the 9P RDMA as the Object Storage Device protocol.
The second risk is Linux community acceptance. Our optimizations must deliver acceptable performance to both desktop and HPC servers of Linux NFS. Even with excellent technical work, however, human factors beyond the scope of this work may lead to lack of community acceptance. In this case we will still have an open-source solution for NFS streaming write performance, but the long term maintenance of the resulting Linux NFS will not be leveraging community
3.4 Unusual Budget Items (if any):
None
4. Strategic Alignment and Potential Benefit
4.1 Relevance to Missions:
4.2 Communication of Results:
We will publish our research, as milestones are met, in peer reviewed journals, conference proceedings and Sandia Reports. Supercomputing, IPDPS, FAST, and the IEEE/Goddard conference are all peer-reviewed and likely places we would find welcome arms. We will also work closely with Center for Information Technology and Integration (CITI) at the University of Michigan to transfer our results to the mainstream Linux community. As milestones are completed, code will be submitted to the Linux kernel tree utilizing the established University of Michigan’s ties.